
ChatGeo-Magi
Large Language Models aided by Retrieval-Augmented Generation for Enhanced Geomagnetic Data Access and Customer Support
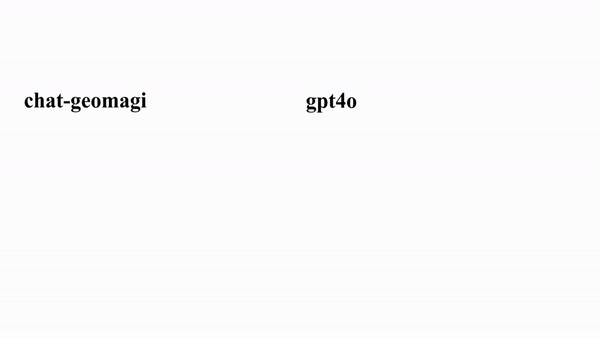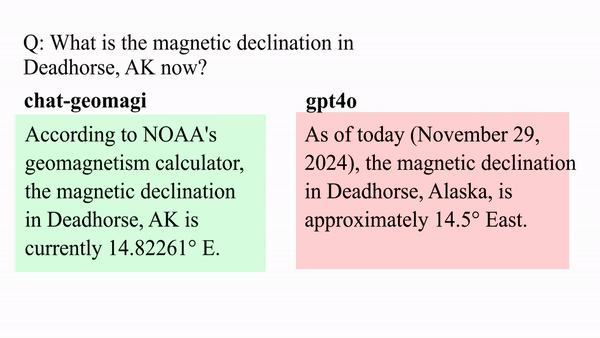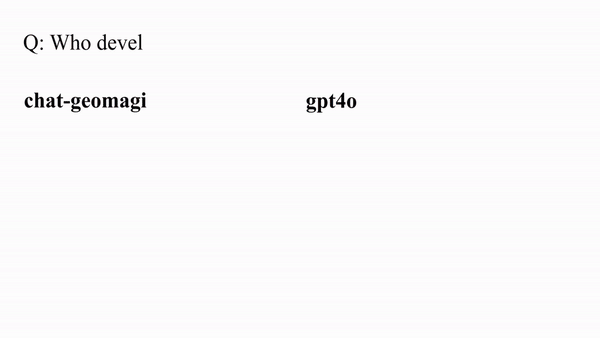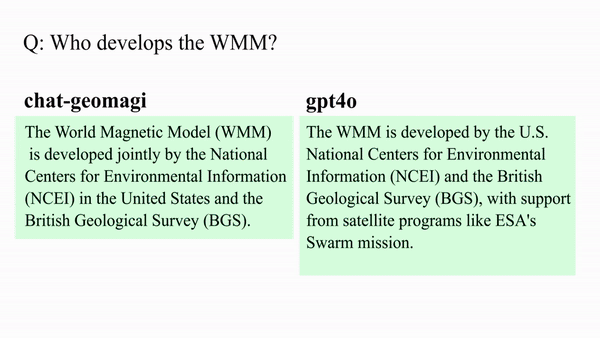
Introduction
The geomagnetism group at NOAA and CIRES develops and distributes models such as the World Magnetic Model (WMM), which supports navigation, mineral exploration, and scientific research. These models are used tens of thousands of times daily, and the need for improved Q&A and customer support interfaces continues to grow. ChatGeo-Magi aims to address this challenge by providing a system capable of reliable explanations, calculator outputs, and data visualization.
ChatGeo-Magi uses a custom agentic approach with Retrieval Augmented Generation (RAG). The system can answer geomagnetic-related questions with authoritative documents as context, and create plots and figures from NOAA’s geomagnetic field calculators.
The Approach
In RAG, documents (technical reports, FAQs, emails) are chunked, embedded, and indexed in a Chroma vector database. Each query is embedded into the same vector space, and the nearest document chunks are retrieved as additional context for the LLM. In the following visualization, a representational vector space is shown. In reality, these vectors would be n-dimensional, with dimensions spanning into the thousands for certain models.
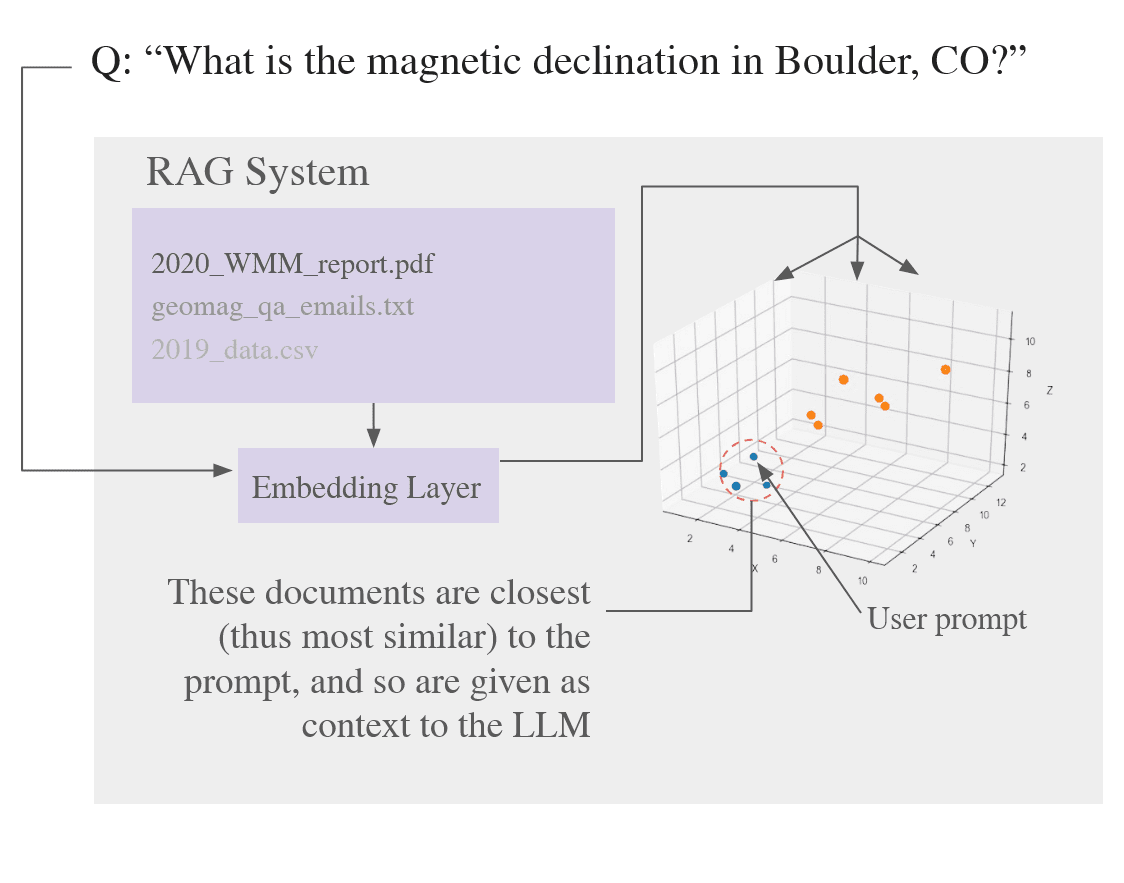
The system is also equipped with tools for querying NOAA’s geomagnetic APIs. For example, a question like “What is the magnetic declination in Deadhorse, Alaska today?” is transformed into a structured API request and executed on behalf of the model. Additional tools support time series plots, multi-series comparisons, and 2D contour mapping of geomagnetic field values. This plot was generated through this system with the prompt of “Plot me the magnetic declination in Alpine Alaska from 2000 until now”

Together, these two methods allow the model to both explain background concepts and return live scientific outputs in the same conversational flow.
Challenges
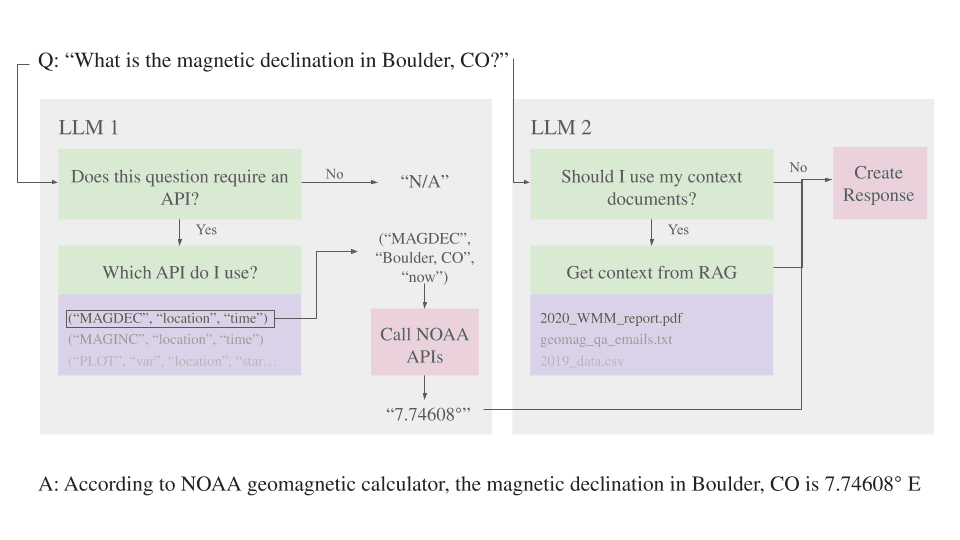
Early versions revealed a limitation, when combining document context and tool usage, the model often ignored or corrupted the syntax needed to call APIs correctly. This made tool execution unreliable.
To mitigate this issue, we created a two-LLM system. The first model is dedicated solely to tool routing. It determines whether a user query requires an API call, and if so, responds with a structured calling syntax. The second model receives RAG context, the user query, and (if applicable) the API response. By dividing responsibilities, syntax errors are reduced and reliability is greatly improved when querying. This approach is demonstrated in the diagram below.
Implementation
The prototype was developed in Python, where ChromaDB would act as the vector database for the documents, Ollama would be used to locally run models, and LlamaIndex was used to orchestrate the full pipeline. The base model shown in the demos above use Gemma2 (27B parameters) on a virtual machine with 2 NVIDIA A100 GPUs.
The agent was made public for workshops and the American Geophysical Union 2024 Meeting via Streamlit.
Ongoing Work
The project remains under active development. Model evaluation platforms like DeepEval and Opik are currently being used to benchmark different base models. The current version additionally uses LangGraph to follow a more agentic workflow.